
Mode - Not another BI tool
Empowering people by making data work simple - a value dlt embodies, and so does Mode. Both tools enable a person to build powerful things “on-the-fly”. Hence, when Mode positions itself as a self-service analytics platform, it delivers on that commitment by offering a user-friendly and familiar interface, and holistic experience.
👨🏻🦰, 👨🏻🦱, and 🧕🏻 from Logistics need to know what happened on the 1st of August, now!
The sad story of most data and analytics teams are as follows: they are frequently burdened with routine (or ad-hoc) data requests, often involving simple SQL commands exported to Excel for external use. Despite the apparent simplicity, handling multiple requests simultaneously creates unnecessary workload. This detracts from the analytics team's capacity to engage in more constructive tasks such as cohort analysis, predictive analysis, hypothesis testing, creating funky plots - the fun stuff!
Nevertheless, employees outside the data team should not be blamed for making data requests without meaningful access to the data. If they were empowered to access and utilize the necessary data independently, individuals like 👨🏻🦰, 👨🏻🦱, and 🧕🏻 could filter user data from August 1st without relying on analysts.
Don’t know where you stand as a company, with data? Ask Mode
You can start your company’s journey with Mode by utilizing their data maturity test. It will tell you where you stand on your data democracy practices. A quick survey of user experiences showed exactly how Mode empowered companies of different sizes to become data thinkers. It has been adopted into 50% of Fortune 500 companies already!
Contrary to common belief, fostering a company-wide embrace of data thinking doesn't necessarily entail teaching everyone programming or conducting data science courses. Mode identifies four pivotal factors—people, processes, culture, and tools—that can empower companies to cultivate data thinkers. However, there are more reasons contributing to Mode's success in facilitating the emergence of company-wide "data heroes”. Let’s explore them.
The ease of adopting Mode
👀 Familiarity & Simple UX
Whether intentional or not, the table view on Mode, alongside by its green and white interface, evokes a sense of familiarity to original BI tool: Excel. Additionally, the platform offers the flexibility of having an SQL-only space and extending that functionality to incorporate Python (and R), providing a user experience similar to utilizing Databricks’ notebook & SQL environment. Lastly, the interface of the dashboarding spaces are the (simplified) experiences of tools like Power BI or Tableau.
When a tool feels familiar, people might embrace it faster. In Mode, all these familiar experiences are combined and simplified into one platform, and this holistic offering could be why Mode is: 1) easy to use and attracts users, and 2) easy to adopt across a company.
🔓 Access Paradigms
Talking about company-wide adoption of a data tool, Mode offers various levels of access tailored to different user roles.
This aligns with the idea behind data democracy, ensuring that individuals throughout the company can engage with data. In Mode, this includes both viewing reports and deriving insights from them, and also viewing the underlying data collection (or datasets). Notably, access can be fine-tuned based on user distinctions, such as developers and business users. This is accomplished through nuanced permission settings and user grouping. By defining specific permissions, one can specify the actions users are empowered to perform. Now, let's explore the specific depth of what these users can actually do with all this power, in the next sections.
💽 SQL & Datasets
Mode stores in itself “datasets”. This goes one step beyond writing a bajillion queries with joins and either saving them as code or saving them as materialized views in your database. You can use SQL and create datasets that are reusable and power a variety of different reports.
Contrast this with the user experience offered by other BI tools, even though they do offer the workspace for table creation, they lack robust documentation and centralization of these tables. It then becomes challenging for other teams (and in a couple of months, yourself) to comprehend the purpose and content of these tables - let alone use them across different reports.
There's no need to switch to a different database engine environment for SQL writing; Mode provides this functionality within its own environment. While tools like Databricks also offer this feature, Mode stands out by seamlessly utilizing it to generate shareable reports, much like the functionality seen in Metabase. Moreover, Mode goes a step further with its integration of Python and R, a capability present in Power BI but notably lacking the user-friendly interface of Mode's notebook environment.
🦉 A single source of truth!
In creating these replicable datasets that can be accessed through different ways, Mode creates a single source of truth. This eliminates the need to search for disparate queries, streamlining the data retrieval (and access) process.
When we discuss data centralization, it typically involves cloud-hosted data warehouses that are accessible to authorized users at any time. This concept extends to business intelligence (BI) as well. Analysts within a company may utilize various tools, different source tables and SQL implementations, such as Apache Superset for business users, and Presto SQL for BI developers in their exploration, this leads to differences in loading and accessing data. Mode, in positioning itself as a central hub for data, resolves this by ensuring uniformity – everyone interacts with the same data source, eliminating variations in querying methods and results.
🔦 Semantic Layers (& dbt)
Speaking of running around for different definitions, we come to the importance of the semantic layer in a data workflow.
In 2022, dbt introduced its semantic layer to address the challenge faced by BI developers and other stakeholders alike, in standardizing metric and indicator definitions across a company. This aimed to resolve issues arising from different individuals querying and defining these metrics, a process prone to human error (or logical code error) that can lead to inconsistencies. The significance of company-wide metrics lies in their impact on investors and their role in guiding teams on measuring growth and determining actions based on that growth.
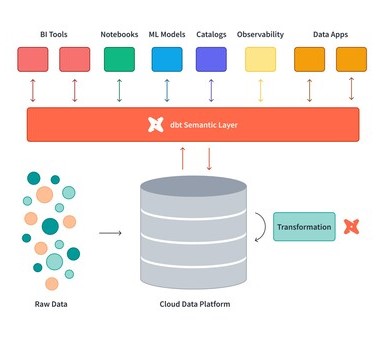
This concept bears some resemblance to the centralized metrics approach described here. However it is integrated into data products, its significance remains crucial. Therefore, incorporating dbt into your pipeline and linking it with Mode can significantly contribute to your journey of data centralization and governance.
Creating the Modern Data Stack with dlt & Mode
Both dlt and Mode share the core value of data democracy, a cornerstone of the Modern Data Stack. When discussing the modern data stack, we are referring to the integration of various modular components that collaboratively create an accessible central system. Typically, this stack begins with a cloud data warehouse, where data is loaded, and updated by a data pipeline tool, like dlt. This process often involves a transformation layer, such as dbt, followed by the utilization of business intelligence (BI) tools like Mode.
In the context of a Python-based environment, one can employ dlt to ingest data into either a database or warehouse destination. Whether this Python environment is within Mode or external to it, dlt stands as its own independent data pipeline tool, responsible for managing the extract and load phases of the ETL process. Additionally, dlt has the ability to structure unstructured data within a few lines of code - this empowers individuals or developers to work independently.
With simplicity, centralization, and governance at its core, the combination of dlt and Mode, alongside a robust data warehouse, establishes two important elements within the modern data stack. Together, they handle data pipeline processes and analytics, contributing to a comprehensive and powerful modern data ecosystem.
There are two ways to use dlt and Mode to uncomplicate your workflows.
1. Extract, Normalize and Load with dlt and Visualize with Mode
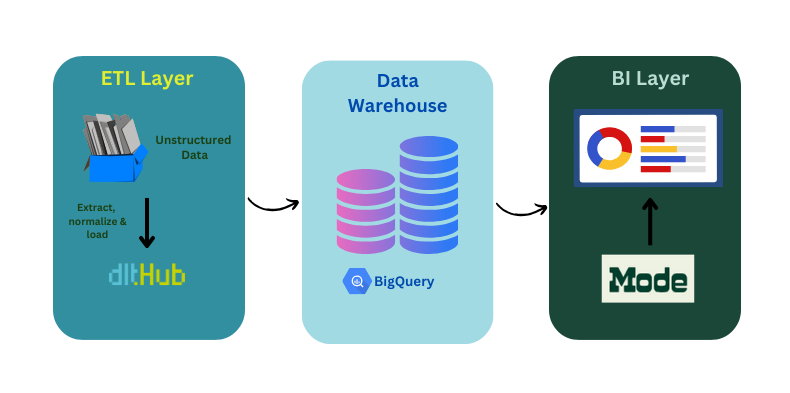
The data we are looking at comes from the source: Shopify. The configuration to initialize a Shopify source can be found in the dltHub docs. Once a dlt pipeline is initialized for Shopify, data from the source can be streamed into the destination of your choice. In this demo, we have chosen for it to be BigQuery destination. From where, it is connected to Mode. Mode’s SQL editor is where you can model your data for reports - removing all unnecessary columns or adding/subtracting the tables you want to be available to teams.
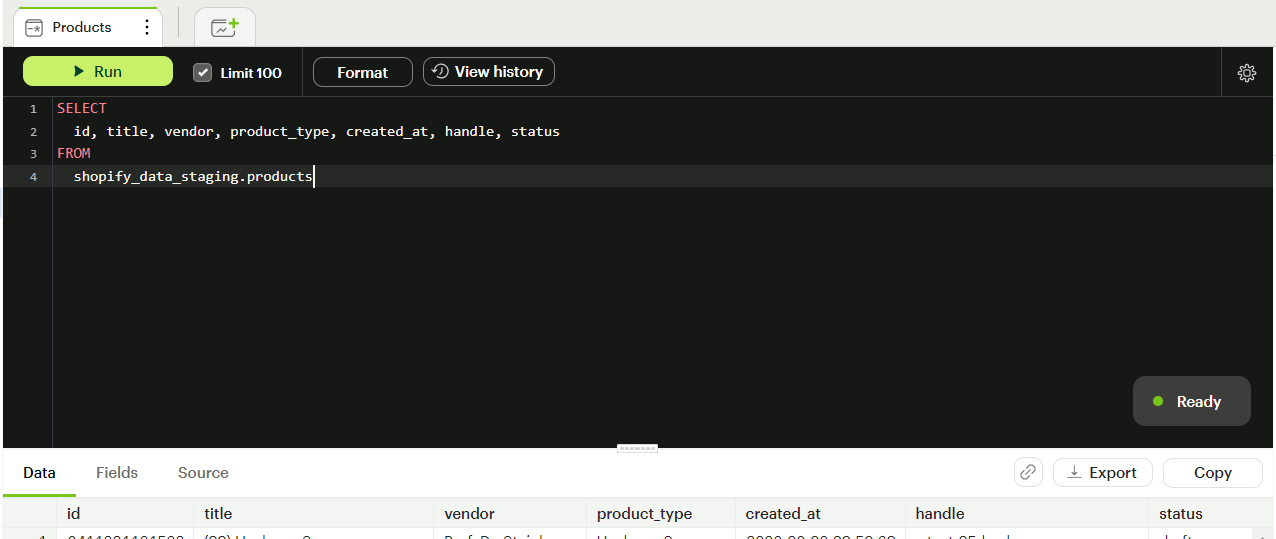
This stage can be perceived as Mode’s own data transformation layer, or semantic modelling layer, depending on which team/designation the user belongs to. Next, the reporting step is also simplified in Mode.
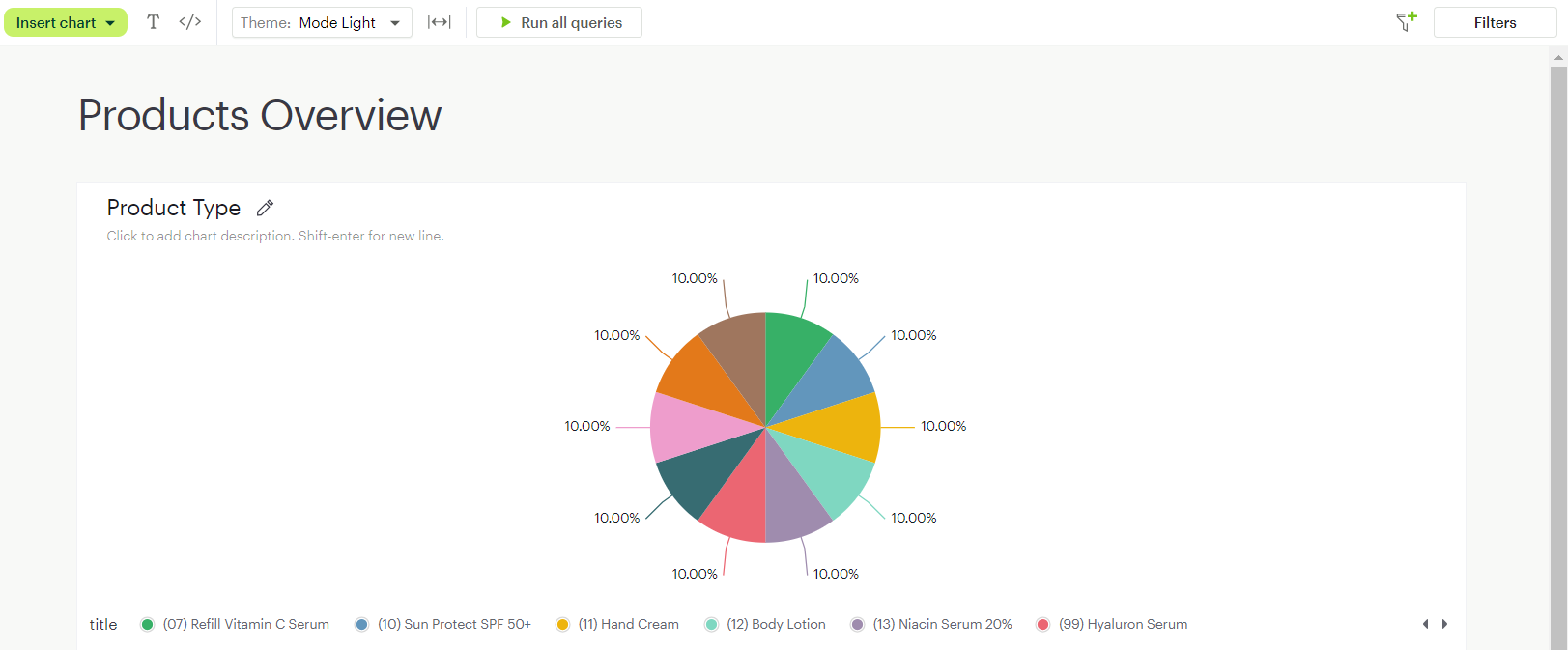
With the model we just created, called Products, a chart can be instantly created and shared via Mode’s Visual Explorer. Once created, it can easily be added to the Report Builder, and added onto a larger dashboard.
2. Use dlt from within the python workspace in Mode
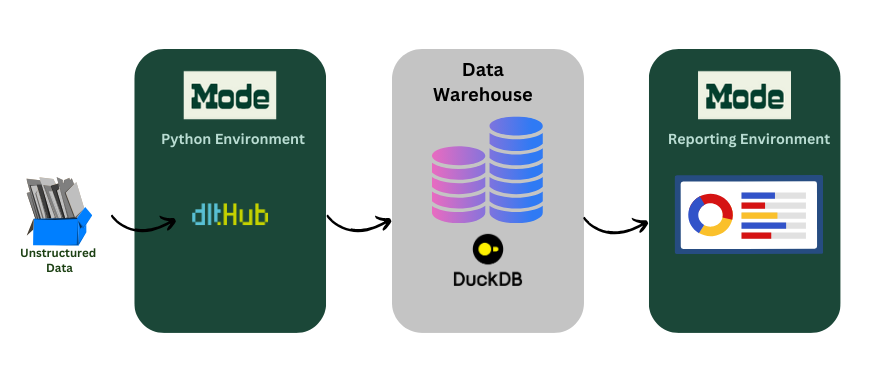
In this demo, we’ll forego the authentication issues of connecting to a data warehouse, and choose the DuckDB destination to show how the Python environment within Mode can be used to initialize a data pipeline and dump normalized data into a destination. In order to see how it works, we first install dlt[duckdb] into the Python environment.
!pip install dlt[duckdb]
Next, we initialize the dlt pipeline:
# initializing the dlt pipeline with your
# data warehouse destination
pipeline = dlt.pipeline(
pipeline_name="mode_example_pipeline",
destination="duckdb",
dataset_name="staging_data")
And then, we pass our data into the pipeline, and check out the load information. Let's look at what the Mode cell outputs:

Let’s check if our pipeline exists within the Mode ecosystem:
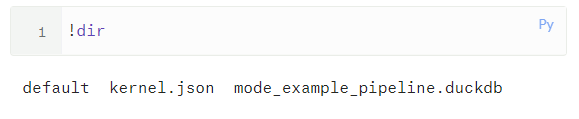
Here we see the pipeline surely exists. Courtesy of Mode, anything that exists within the pipeline that we can query through Python can also be added to the final report or dashboard using the “Add to Report” button.
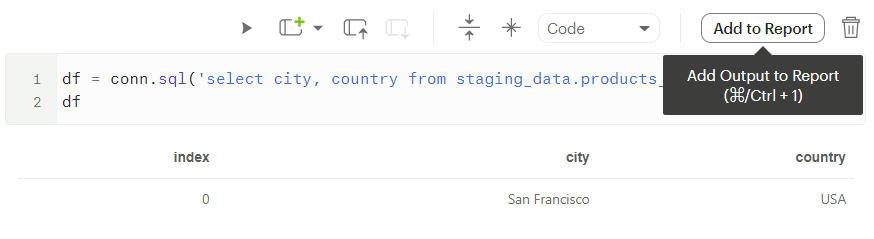
Once a pipeline is initialized within Mode’s Python environment, the Notebook cell can be frozen, and every consecutive run of the notebook can be a call to the data source, updating the data warehouse and reports altogether!
Conclusion
dlt and Mode can be used together using either method, and make way for seamless data workflows. The first method mentioned in this article is the more traditional method of creating a data stack, where each tool serves a specific purpose. The second method, however utilizes the availability of a Python workspace within Mode to also serve the ETL process within Mode as well. This can be used for either ad-hoc reports and ad hoc data sources that need to be viewed visually, or, can be utilized as a proper pipeline creation and maintenance tool.