Getting Started
Overview
dlt is an open-source library that you can add to your Python scripts to load data
from various and often messy data sources into well-structured, live datasets.
Below we give you a preview how you can get data from APIs, files, Python objects or
pandas dataframes and move it into a local or remote database, data lake or a vector data store.
Let's get started!
Installation
Install dlt using pip:
pip install -U dlt
Command above installs (or upgrades) library core, in example below we use duckdb as a destination so let's add it:
pip install "dlt[duckdb]"
Use clean virtual environment for your experiments! Here are detailed instructions.
Make sure that your dlt version is 0.3.15 or above. Check it in the terminal with dlt --version.
Quick start
Let's load a list of Python objects (dictionaries) into duckdb and inspect the created dataset:
import dlt
data = [
{'id': 1, 'name': 'Alice'},
{'id': 2, 'name': 'Bob'}
]
pipeline = dlt.pipeline(
pipeline_name='quick_start',
destination='duckdb',
dataset_name='mydata'
)
load_info = pipeline.run(data, table_name="users")
print(load_info)
Save this python script with the name quick_start_pipeline.py and run the following command:
python quick_start_pipeline.py
The output should look like:
Pipeline quick_start completed in 0.59 seconds
1 load package(s) were loaded to destination duckdb and into dataset mydata
The duckdb destination used duckdb:////home/user-name/quick_start/quick_start.duckdb location to store data
Load package 1692364844.460054 is LOADED and contains no failed jobs
dlt just created a database schema called mydata (the dataset_name) with a table users in it.
Take a look at it using built-in Streamlit app:
dlt pipeline quick_start show
quick_start is the name of the pipeline from the script above. If you do not have Streamlit installed yet do:
pip install streamlit
Now you should see the users table:
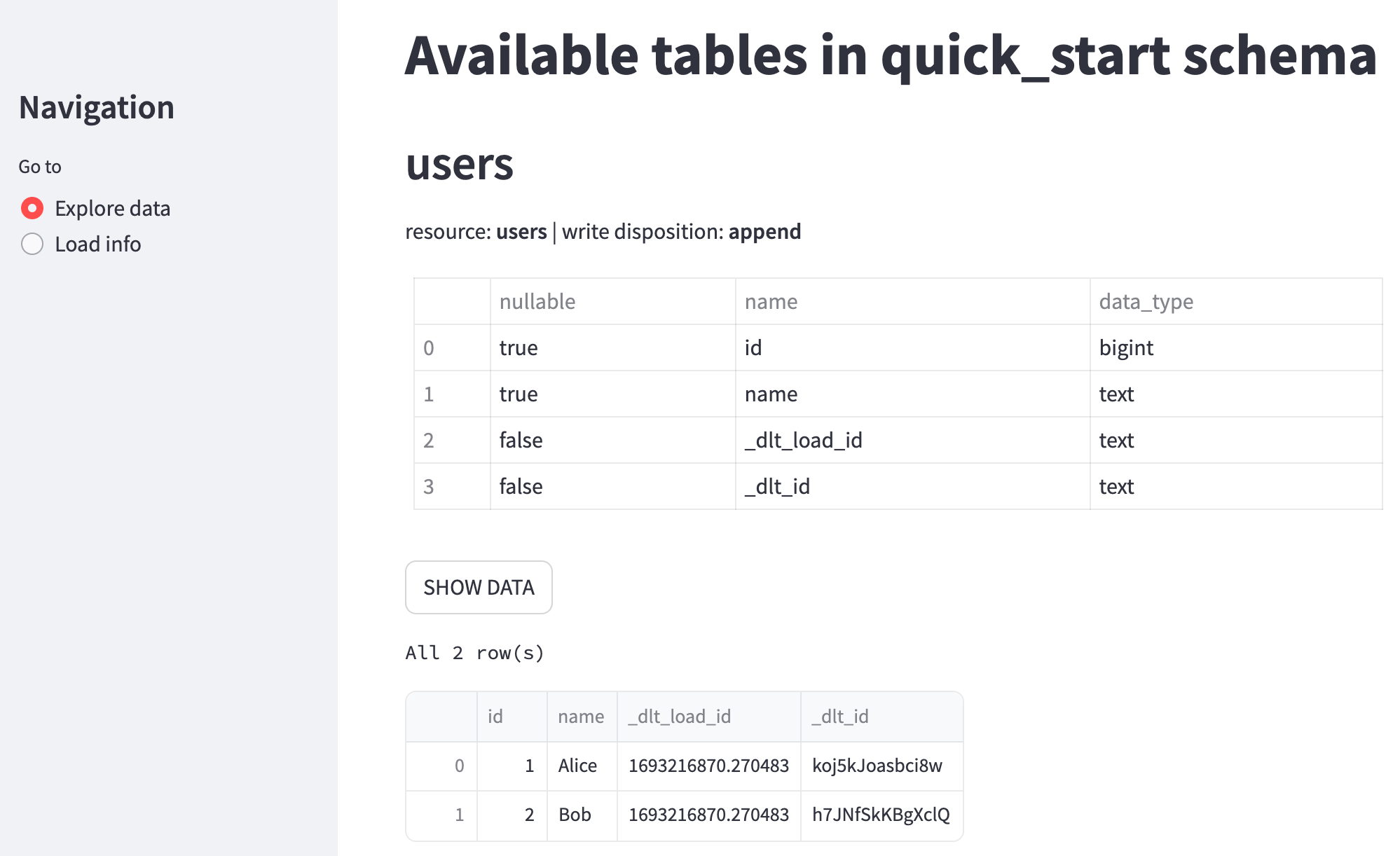 Streamlit Explore data. Schema and data for a test pipeline “quick_start”.
Streamlit Explore data. Schema and data for a test pipeline “quick_start”.
dlt works in Jupyter Notebook and Google Colab! See our Quickstart Colab Demo.
Looking for source code of all the snippets? You can find and run them from this repository.
Learn more:
- What is a data pipeline? General usage: Pipeline.
- Walkthrough: Create a pipeline.
- Walkthrough: Run a pipeline.
- How to configure DuckDB? Destinations: DuckDB.
- The full list of available destinations.
- Exploring the data.
- What happens after loading? Destination tables.
Load your data
Load data from a variety of sources
Use dlt to load practically any data you deal with in your Python scripts into a dataset. The library will create/update tables, infer data types and deal with nested data automatically:
- from JSON
- from CSV/XLS/Pandas
- from API
- from Database
import dlt
from dlt.common import json
with open("./assets/json_file.json", 'rb') as file:
data = json.load(file)
pipeline = dlt.pipeline(
pipeline_name='from_json',
destination='duckdb',
dataset_name='mydata',
)
# NOTE: test data that we load is just a dictionary so we enclose it in a list
# if your JSON contains a list of objects you do not need to do that
load_info = pipeline.run([data], table_name="json_data")
print(load_info)
We import json from dlt namespace. It defaults to orjson(otherwise simplejson). It can also encode date times, dates, dataclasses and few more data types.
Pass anything that you can load with Pandas to dlt
import dlt
import pandas as pd
owid_disasters_csv = "https://raw.githubusercontent.com/owid/owid-datasets/master/datasets/Natural%20disasters%20from%201900%20to%202019%20-%20EMDAT%20(2020)/Natural%20disasters%20from%201900%20to%202019%20-%20EMDAT%20(2020).csv"
df = pd.read_csv(owid_disasters_csv)
data = df.to_dict(orient='records')
pipeline = dlt.pipeline(
pipeline_name='from_csv',
destination='duckdb',
dataset_name='mydata',
)
load_info = pipeline.run(data, table_name="natural_disasters")
print(load_info)
import dlt
from dlt.sources.helpers import requests
# url to request dlt-hub/dlt issues
url = "https://api.github.com/repos/dlt-hub/dlt/issues"
# make the request and check if succeeded
response = requests.get(url)
response.raise_for_status()
pipeline = dlt.pipeline(
pipeline_name='from_api',
destination='duckdb',
dataset_name='github_data',
)
# the response contains a list of issues
load_info = pipeline.run(response.json(), table_name="issues")
print(load_info)
Use our verified sql database source to sync your databases with warehouses, data lakes, or vector stores.
import dlt
from sqlalchemy import create_engine
# use any sql database supported by SQLAlchemy, below we use a public mysql instance to get data
# NOTE: you'll need to install pymysql with "pip install pymysql"
# NOTE: loading data from public mysql instance may take several seconds
engine = create_engine("mysql+pymysql://rfamro@mysql-rfam-public.ebi.ac.uk:4497/Rfam")
with engine.connect() as conn:
# select genome table, stream data in batches of 100 elements
rows = conn.execution_options(yield_per=100).exec_driver_sql("SELECT * FROM genome LIMIT 1000")
pipeline = dlt.pipeline(
pipeline_name='from_database',
destination='duckdb',
dataset_name='genome_data',
)
# here we convert the rows into dictionaries on the fly with a map function
load_info = pipeline.run(
map(lambda row: dict(row._mapping), rows),
table_name="genome"
)
print(load_info)
Install pymysql driver:
pip install pymysql
Have some fun and run this snippet with progress bar enabled (we like enlighten the best, tqdm works as well):
pip install enlighten
PROGRESS=enlighten python load_from_db.py
Append or replace your data
Run any of the previous examples twice to notice that each time a copy of the data is added to your tables.
We call this load mode append. It is very useful when i.e. you have a new folder created daily with json file logs, and you want to ingest them.
Perhaps this is not what you want to do in the examples above.
For example, if the CSV file is updated, how we can refresh it in the database?
One method is to tell dlt to replace the data in existing tables by using write_disposition:
import dlt
data = [
{'id': 1, 'name': 'Alice'},
{'id': 2, 'name': 'Bob'}
]
pipeline = dlt.pipeline(
pipeline_name='replace_data',
destination='duckdb',
dataset_name='mydata',
)
load_info = pipeline.run(data, table_name="users", write_disposition="replace")
print(load_info)
Run this script twice to see that users table still contains only one copy of your data.
What if you added a new column to your CSV?
dlt will migrate your tables!
See the replace mode and table schema migration in action in our Colab Demo.
Learn more:
Declare loading behavior
You can define the loading process by decorating Python functions with @dlt.resource.
Load only new data (incremental loading)
We can improve the GitHub API example above and get only issues that were created since last load.
Instead of using replace write_disposition and downloading all issues each time the pipeline is run, we do the following:
import dlt
from dlt.sources.helpers import requests
@dlt.resource(table_name="issues", write_disposition="append")
def get_issues(
created_at=dlt.sources.incremental("created_at", initial_value="1970-01-01T00:00:00Z")
):
# NOTE: we read only open issues to minimize number of calls to the API. There's a limit of ~50 calls for not authenticated Github users
url = "https://api.github.com/repos/dlt-hub/dlt/issues?per_page=100&sort=created&directions=desc&state=open"
while True:
response = requests.get(url)
response.raise_for_status()
yield response.json()
# stop requesting pages if the last element was already older than initial value
# note: incremental will skip those items anyway, we just do not want to use the api limits
if created_at.start_out_of_range:
break
# get next page
if "next" not in response.links:
break
url = response.links["next"]["url"]
pipeline = dlt.pipeline(
pipeline_name='github_issues_incremental',
destination='duckdb',
dataset_name='github_data_append',
)
load_info = pipeline.run(get_issues)
row_counts = pipeline.last_trace.last_normalize_info
print(row_counts)
print("------")
print(load_info)
We request issues for dlt-hub/dlt repository ordered by created_at field (descending) and yield them page by page in get_issues generator function.
We use the @dlt.resource decorator to declare table name to which data will be loaded and write disposition, which is append.
We also use dlt.sources.incremental to track created_at field present in each issue to filter in the newly created.
Now run the script. It loads all the issues from our repo to duckdb. Run it again, and you can see that no issues got added (if no issues were created in the meantime).
Now you can run this script on a daily schedule and each day you’ll load only issues created after the time of the previous pipeline run.
Between pipeline runs, dlt keeps the state in the same database it loaded data to.
Peek into that state, the tables loaded and get other information with:
dlt pipeline -v github_issues_incremental info
Learn more:
- Declare your resources and group them in sources using Python decorators.
- Set up "last value" incremental loading.
- Inspect pipeline after loading.
dltcommand line interface.
Update and deduplicate your data
The script above finds new issues and adds them to the database.
It will ignore any updates to existing issue text, emoji reactions etc.
To get always fresh content of all the issues you combine incremental load with merge write disposition,
like in the script below.
import dlt
from dlt.sources.helpers import requests
@dlt.resource(
table_name="issues",
write_disposition="merge",
primary_key="id",
)
def get_issues(
updated_at = dlt.sources.incremental("updated_at", initial_value="1970-01-01T00:00:00Z")
):
# NOTE: we read only open issues to minimize number of calls to the API. There's a limit of ~50 calls for not authenticated Github users
url = f"https://api.github.com/repos/dlt-hub/dlt/issues?since={updated_at.last_value}&per_page=100&sort=updated&directions=desc&state=open"
while True:
response = requests.get(url)
response.raise_for_status()
yield response.json()
# get next page
if "next" not in response.links:
break
url = response.links["next"]["url"]
pipeline = dlt.pipeline(
pipeline_name='github_issues_merge',
destination='duckdb',
dataset_name='github_data_merge',
)
load_info = pipeline.run(get_issues)
row_counts = pipeline.last_trace.last_normalize_info
print(row_counts)
print("------")
print(load_info)
Above we add primary_key hint that tells dlt how to identify the issues in the database to find duplicates which content it will merge.
Note that we now track the updated_at field - so we filter in all issues updated since the last pipeline run (which also includes those newly created).
Pay attention how we use since parameter from GitHub API
and updated_at.last_value to tell GitHub to return issues updated only after the date we pass. updated_at.last_value holds the last updated_at value from the previous run.
Learn more:
Dispatch stream of events to tables by event type
This is a fun but practical example that reads GitHub events from dlt repository (such as issue or pull request created, comment added etc.).
Each event type is sent to a different table in duckdb.
import dlt
from dlt.sources.helpers import requests
@dlt.resource(primary_key="id", table_name=lambda i: i["type"], write_disposition="append")
def repo_events(
last_created_at = dlt.sources.incremental("created_at")
):
url = "https://api.github.com/repos/dlt-hub/dlt/events?per_page=100"
while True:
response = requests.get(url)
response.raise_for_status()
yield response.json()
# stop requesting pages if the last element was already older than initial value
# note: incremental will skip those items anyway, we just do not want to use the api limits
if last_created_at.start_out_of_range:
break
# get next page
if "next" not in response.links:
break
url = response.links["next"]["url"]
pipeline = dlt.pipeline(
pipeline_name='github_events',
destination='duckdb',
dataset_name='github_events_data',
)
load_info = pipeline.run(repo_events)
row_counts = pipeline.last_trace.last_normalize_info
print(row_counts)
print("------")
print(load_info)
Events content never changes so we can use append write disposition and track new events using created_at field.
We name the tables using a function that receives an event data and returns table name: table_name=lambda i: i["type"]
Now run the script:
python github_events_dispatch.py
Peek at created tables:
dlt pipeline -v github_events info
dlt pipeline github_events trace
And preview the data:
dlt pipeline -v github_events show
Some of the events produce tables with really many child tables. You can control the level of table nesting with a decorator.
Another fun Colab Demo - we analyze reactions on duckdb repo!
Learn more:
- Change nesting of the tables with a decorator.
Transform the data before the load
Below we extract text from PDFs and load it to Weaviate vector store.
import os
import dlt
from dlt.destinations.weaviate import weaviate_adapter
from PyPDF2 import PdfReader
@dlt.resource(selected=False)
def list_files(folder_path: str):
folder_path = os.path.abspath(folder_path)
for filename in os.listdir(folder_path):
file_path = os.path.join(folder_path, filename)
yield {
"file_name": filename,
"file_path": file_path,
"mtime": os.path.getmtime(file_path)
}
@dlt.transformer(primary_key="page_id", write_disposition="merge")
def pdf_to_text(file_item, separate_pages: bool = False):
if not separate_pages:
raise NotImplementedError()
# extract data from PDF page by page
reader = PdfReader(file_item["file_path"])
for page_no in range(len(reader.pages)):
# add page content to file item
page_item = dict(file_item)
page_item["text"] = reader.pages[page_no].extract_text()
page_item["page_id"] = file_item["file_name"] + "_" + str(page_no)
yield page_item
pipeline = dlt.pipeline(
pipeline_name='pdf_to_text',
destination='weaviate'
)
# this constructs a simple pipeline that: (1) reads files from "invoices" folder (2) filters only those ending with ".pdf"
# (3) sends them to pdf_to_text transformer with pipe (|) operator
pdf_pipeline = list_files("assets/invoices").add_filter(
lambda item: item["file_name"].endswith(".pdf")
) | pdf_to_text(separate_pages=True)
# set the name of the destination table to receive pages
# NOTE: Weaviate, dlt's tables are mapped to classes
pdf_pipeline.table_name = "InvoiceText"
# use weaviate_adapter to tell destination to vectorize "text" column
load_info = pipeline.run(
weaviate_adapter(pdf_pipeline, vectorize="text")
)
row_counts = pipeline.last_trace.last_normalize_info
print(row_counts)
print("------")
print(load_info)
We start with a simple resource that lists files in specified folder. To that we add a filter function that removes all files that are not pdfs.
To parse PDFs we use PyPDF and return each page from a given PDF as separate data item.
Parsing happens in @dlt.transformer which receives data from list_files resource. It splits PDF into pages, extracts text and yields pages separately
so each PDF will correspond to many items in Weaviate InvoiceText class. We set the primary key and use merge disposition so if the same PDF comes twice
we'll just update the vectors, and not duplicate.
Look how we pipe data from list_files resource (note that resource is deselected so we do not load raw file items to destination) into pdf_to_text using | operator.
Just before load, the weaviate_adapter is used to tell weaviate destination which fields to vectorize.
To run this example you need additional dependencies:
pip install PyPDF2 "dlt[weaviate]"
python pdf_to_weaviate.py
Now it is time to query our documents.
import weaviate
client = weaviate.Client("http://localhost:8080")
# get text of all the invoices in InvoiceText class we just created above
print(client.query.get("InvoiceText", ["text", "file_name", "mtime", "page_id"]).do())
Above we provide URL to local cluster. We also use contextionary to vectorize data. You may find information on our setup in links below.
Change the destination to duckdb if you do not have access to Weaviate cluster or not able to run it locally.
Learn more:
- Setup Weaviate destination - local or cluster.
- Connect the transformers to the resources to load additional data or enrich it.
- Transform your data before loading and see some examples of customizations like column renames and anonymization.
Next steps
If you want to take full advantage of the dlt library, then we strongly suggest that you build your sources out of existing building blocks:
- Pick your destinations.
- Check verified sources provided by us and community.
- Access your data with SQL or Pandas.
- Declare your resources and group them in sources using Python decorators.
- Connect the transformers to the resources to load additional data or enrich it.
- Create your resources dynamically from data.
- Append, replace and merge your tables.
- Transform your data before loading and see some examples of customizations like column renames and anonymization.
- Set up "last value" incremental loading.
- Set primary and merge keys, define the columns nullability and data types.
- Pass config and credentials into your sources and resources.
- Use built-in requests client.
- Run in production: inspecting, tracing, retry policies and cleaning up.
- Run resources in parallel, optimize buffers and local storage